

در اولین مقاله از این سری، در مورد مفاهیم اولیه HTTP صحبت کردیم. اکنون که پایهای برای ساخت بنای معماری را در اختیار داریم، میتوانیم در مورد برخی از جنبههای معماری HTTP صحبت کنیم. برای HTTP چیزهای بیش از فقط ارسال و دریافت داده وجود دارد.
HTTP به خودی خود نمی تواند به عنوان یک پروتکل اپلیکیشن عمل کند. HTTP نیاز به زیرساختهایی در قالب راهحلهای سختافزاری و نرمافزاری دارد که خدمات مختلفی را ارائه کرده و ارتباط بر روی شبکه جهانی وب را ممکن و کارآمد کند.
این دومین قسمت از سری HTTP است.
در این مقاله با موارد زیر بیشتر آشنا خواهید شد:
اینها بخشی جدایی ناپذیر از زندگی اینترنتی ما هستند و شما دقیقاً خواهید آموخت که هدف هر یک از اینها چیست و چگونه کار می کنند. دانش دانستن اینها به شما کمک می کند تا قسمتهای موجود در مقاله اول را به هم متصل کرده و جریان ارتباط HTTP را حتی بهتر درک کنید.
بنابراین اجازه دهید تا شروع کنیم.
Web Server ها
همانطور که در مقاله اول توضیح داده شد، وظیفه اصلی یک وب سرور، ذخیره منابع و به کارگیری آنها پس از دریافت request ها است. شما با استفاده از یک سرویس گیرنده وب (معروف به مرورگر وب) به وب سرور دسترسی پیدا می کنید و در عوض منابع درخواستی را دریافت می کنید یا وضعیت منابع موجود را تغییر می دهید.
با استفاده از خزنده های وب (Web crawler ها) نیز می توان به طور خودکار به سرورهای وب دسترسی پیدا کرد که در ادامه مقاله در مورد آنها صحبت خواهیم کرد.

برخی از محبوب ترین وب سرورهای موجود و احتمالاً آنهایی که نام آنها را شنیده اید عبارتند از Apache HTTP Server، Nginx، IIS، Glassfish…
وب سرورها می توانند از نرم افزارهای بسیار ساده و آسان تا نرم افزارهای پیچیده و پیشرفته متفاوت باشند. وب سرورهای مدرن قادر به انجام بسیاری از وظایف مختلف هستند. وظایف اصلی که وب سرور باید بتواند انجام دهد:
- تنظیم connection – پذیرفتن یا رد کردن connection کلاینت
- دریافت request – خواندن یک پیام HTTP request
- پردازش request – پردازش کردن پیام request و اقدام کردن
- دسترسی به منابع – دسترسی به منابع مشخص شده در پیام
- ایجاد response – ایجاد پیام HTTP response
- ارسال response – برگرداندن response به client
- Log کردن transaction – نوشتن تراکنش تکمیل شده در یک فایل log
من جریان اصلی وب سرور را در چند فاز مختلف تقسیم خواهم کرد. این مراحل نشان دهنده یک نسخه بسیار ساده شده از جریان وب سرور است.
فاز 1: راه اندازی یک connection
هنگامی که سرویس گیرنده وب می خواهد به وب سرور دسترسی پیدا کند، باید سعی کند یک اتصال TCP جدید را باز کند. از طرف دیگر، سرور سعی می کند آدرس IP کلاینت را استخراج کند. پس از آن، این به سرور بستگی دارد که تصمیم بگیرد اتصال TCP را برای آن کلاینت باز کند یا ببندد.
اگر سرور، connection را بپذیرد، سپس آن را به لیست connection های موجود اضافه می کند و داده های مربوط به آن connection را مشاهده می کند.
همچنین اگر کلاینت مجاز نباشد یا در لیست سیاه (مخرب) باشد، می تواند connection را ببندد.
سرور همچنین می تواند با استفاده از “DNS معکوس” نام host کلاینت را شناسایی کند. این اطلاعات میتواند هنگام لاگ شدن پیامها کمک کننده باشد، اما جستجوی نام host ممکن است کمی طول بکشد و تراکنشها را کند کند.
فاز 2: دریافت / پردازش request ها
هنگام تجزیه درخواست های ورودی، سرورهای وب، اطلاعات را از خط پیام درخواست، header ها و body (در صورت ارائه) تجزیه می کند. نکته ای که باید به آن توجه داشت این است که connection می تواند در هر زمان متوقف شود و در این صورت سرور باید تا زمانی که بقیه داده ها را دریافت کند، اطلاعات را به طور موقت ذخیره کند.
وب سرورهای سطح بالا باید بتوانند بسیاری از connection های همزمان را باز کنند. این شامل چندین connection همزمان از یک کلاینت است. یک صفحه وب نمونه می تواند منابع مختلفی را از سرور درخواست کند.
فاز 3: دسترسی به منابع
از آنجایی که وب سرورها در درجه اول تامین کننده منابع هستند، راه های متعددی برای مپ کردن و دسترسی به منابع دارند.
ساده ترین راه برای مپ کردن منبع، استفاده از URI درخواست برای یافتن فایل در filesystem وب سرور است. به طور معمول، وب سرور آنها را در یک پوشه خاص به نام docroot قرار می دهد. به عنوان مثال، docroot در ویندوز سرور می تواند در \F:\WebResources قرار گیرد. اگر درخواست GET بخواهد به فایل در images/expertmarketblog.txt/ دسترسی پیدا کند، سرور این را به آدرس F:\WebResources\images\expertmarketblog.txt تفسیر می کند و آن فایل را در پیام response برمی گرداند. هنگامی که بیش از یک وب سایت بر روی یک وب سرور میزبانی می شود، هر یک می توانند docroot جداگانه خود را داشته باشند.
اگر وب سرور به جای درخواست به یک فایل، درخواستی برای یک دایرکتوری دریافت کند، می تواند آن درخواست را به چند روش پاسخ دهد. می تواند یک پیام خطا برگرداند، فایل پیش فرض index را به جای دایرکتوری برگرداند یا دایرکتوری را اسکن کرده و فایل HTML را با محتویات برگرداند.
سرور همچنین ممکن است URI درخواست را به منبع داینامیک مپ کند – یک برنامه نرم افزاری که نتایجی را تولید می کند. یک کلاس کامل از سرورها به نام سرورهای application وجود دارد که هدف آنها اتصال سرورهای وب به راه حل های پیچیده نرم افزاری و ارائه محتوای داینامیک است.
فاز 3: تولید و ارسال response
هنگامی که سرور منبعی را که برای سرویس دادن نیاز دارد شناسایی کرد، پیام response را مهیا میکند. پیام response، در صورت نیاز حاوی کد response header ،status ها و response body است.
اگر body در response وجود داشته باشد، پیام معمولاً حاوی هدر Content-Length است که اندازه body را توصیف می کند و همچنین حاوی هدر Content-Type است که MIME type منبع برگشتی را توصیف می کند.
پس از ایجاد response، سرور کلاینت مورد نیاز برای ارسال response را انتخاب می کند. برای connection های غیرپایدار، سرور باید زمانی که کل پیام response ارسال شد، connection را ببندد.
فاز 4: Logging
هنگامی که تراکنش کامل شد، سرور تمام اطلاعات تراکنش را در فایل ثبت می کند. بسیاری از سرورها، سفارشی سازی های مربوط به Logging را ارائه می دهند.
Proxy Server ها
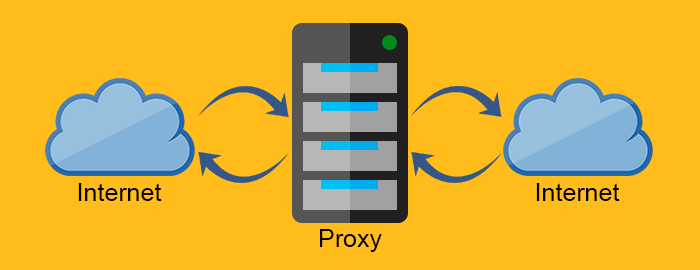
سرورهای Proxy (پروکسی ها) سرورهای واسطه هستند. آنها اغلب بین Web server و Web client یافت می شوند. به دلیل ماهیت آنها، سرورهای پروکسی باید هم مانند یک سرویس گیرنده وب و هم مانند یک وب سرور رفتار کند.
اما چرا به سرورهای پروکسی نیاز داریم؟ چرا فقط به طور مستقیم بین Web client ها و Web server ها ارتباط برقرار نمی کنیم؟ آیا به طور مستقیم، خیلی ساده تر و سریع تر نیست؟
خوب، ممکن است ساده باشد، اما سریعتر، نه واقعا. اما به آن خواهیم پرداخت.
قبل از اینکه توضیح دهیم که سرورهای پروکسی چیست، باید یک چیز را مشخص کنیم. آن چیز، مفهوم reverse proxy یا تفاوت بین forward proxy و reverse proxy است.
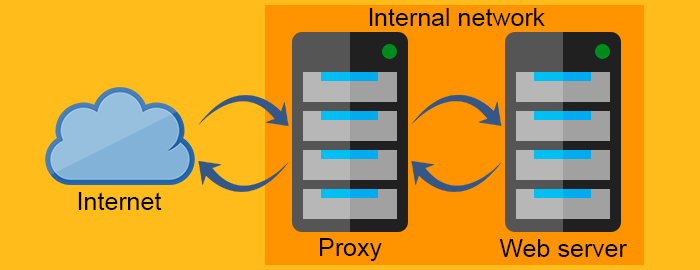
forward proxy به عنوان یک proxy برای client که منبع را از Web server درخواست می کند عمل می کند. این proxy، با فیلتر کردن درخواست ها از طریق firewall یا مخفی کردن اطلاعات مربوط به client، از client محافظت می کند. از طرف دیگر، reverse proxy دقیقاً برعکس عمل می کند. معمولاً در پشت firewall قرار می گیرد و از Web server ها محافظت می کنند. برای اینکه تمام client ها بدانند، آنها با وب سرور واقعی صحبت می کنند و از شبکه پشت reverse proxy بی اطلاع می مانند.
Proxy server
Reverse proxy server
پروکسی ها بسیار مفید هستند و کاربرد آنها بسیار گسترده است.
بریم تا برخی از شیوه هایی را که میتوانید از سرورهای پروکسی استفاده کنید را با هم مرور کنیم.
- فشرده سازی – فشرده سازی محتوا به طور مستقیم سرعت ارتباط را افزایش می دهد. به همین سادگی.
- نظارت و فیلتر کردن – آیا میخواهید دسترسی به وبسایتهای بزرگسالان را برای کودکان دبستانی ممنوع کنید؟ پروکسی راه حل مناسبی برای شماست.
- امنیت – پروکسی ها می توانند به عنوان یک نقطه ورودی واحد برای کل شبکه عمل کنند. آنها می توانند برنامه های مخرب را شناسایی کرده و پروتکل های سطح application را محدود کنند.
- ناشناس بودن – منابع برای اینکه بیشتر ناشناس باقی بمانند میتوانند توسط proxy اصلاح شوند. proxy می تواند اطلاعات حساس را از درخواست حذف کند و فقط موارد مهم را باقی بگذارد. اگرچه ارسال اطلاعات کمتر به سرور ممکن است تجربه کاربر را کاهش دهد، اما گاهی اوقات ناشناس بودن، عامل مهمتری است.
- کنترل دسترسی – بسیار ساده است، می توانید کنترل دسترسی بسیاری از سرورها را روی یک سرور پراکسی واحد متمرکز کنید.
- Caching – می توانید از سرور proxy برای کش کردن محتوای محبوب استفاده کنید و در نتیجه سرعت بارگذاری را تا حد زیادی کاهش دهید.
- متعادل سازی بار (Load balancing) – اگر سرویسی دارید که “اوج ترافیک” زیادی دریافت می کند، می توانید از یک پروکسی برای توزیع بار کاری در منابع محاسباتی یا سرورهای وب بیشتر استفاده کنید. متعادل کننده های بار، ترافیک را هدایت می کنند تا از بارگذاری بیش از حد سرور منفرد در زمان اوج گیری ترافیک جلوگیری کنند.
- Transcoding – تغییر محتوای body پیام نیز می تواند مسئولیت پروکسی باشد.
همانطور که می بینید، پروکسی ها می توانند بسیار متنوع و انعطاف پذیر باشند.
Caching
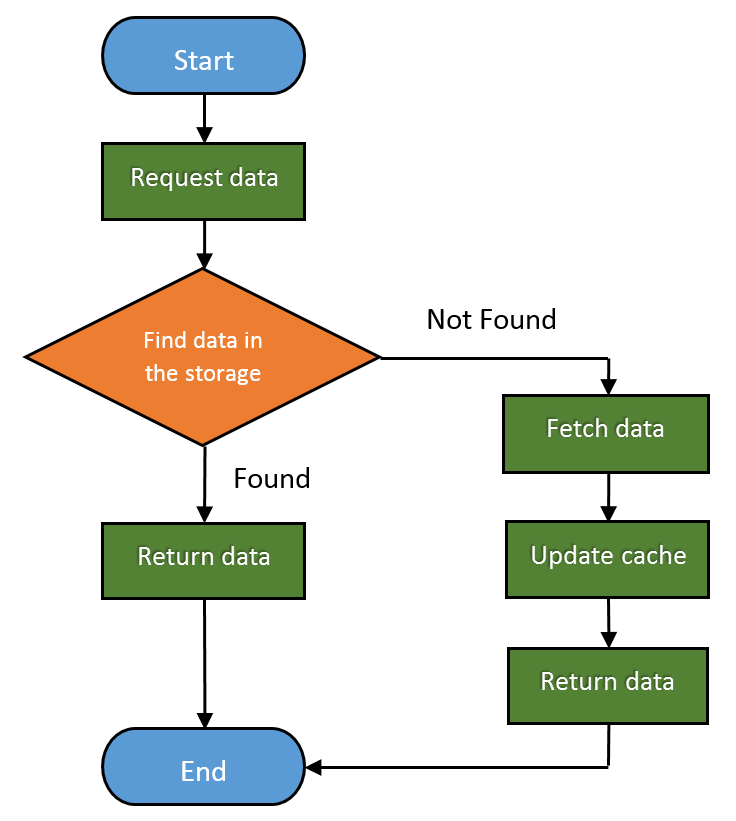
Web cache ها، دستگاه هایی هستند که به طور خودکار از داده های درخواستی کپی می کنند و آنها را در حافظه محلی ذخیره می کنند.
با انجام این کار، آنها می توانند:
- جریان ترافیک را کاهش دهند
- عاملهای کند کننده شبکه را از بین ببرند
- از اضافه بار سرور جلوگیری کنند
- تأخیر در پاسخ را در فواصل طولانی کاهش دهند
بنابراین به وضوح می توان گفت که Web cache ها، هم تجربه کاربری و هم عملکرد وب سرور را بهبود می بخشند و البته، به طور بالقوه در هزینه های زیادی نیز صرفه جویی میشود.
میزان درخواست های ارائه شده از cache، نرخ ضربه (Hit Rate) نامیده می شود. می تواند از 0 تا 1 متغیر باشد، که در آن 0 به معنی 0٪ و 1 به معنی 100٪ درخواست ارائه شده است.
در اینجا نحوه جریان کار پایه Web cache به شرح زیر است:
Gateway ها, Tunnel ها و Relay ها
با گذشت زمان، همانطور که HTTP به بلوغ رسید، مردم راه های مختلفی برای استفاده از آن پیدا کردند. HTTP به عنوان چارچوبی برای اتصال اپلیکیشنها و پروتکل های مختلف مفید واقع قرار گرفت.
اما ببینیم چطور این اتفاق افتاده است.
Gateway ها
Gateway ها به قطعات سختافزاری اطلاق میشوند که میتوانند HTTP را قادر سازند تا با انتزاعی کردن راهی برای دریافت یک منبع، با پروتکلها و اپلیکیشنهای مختلف ارتباط برقرار کنند. آنها همچنین مبدل پروتکل نامیده می شوند و به دلیل استفاده از چندین پروتکل، بسیار پیچیده تر از روترها یا سوئیچ ها هستند.
برای مثال میتوانید با ارسال درخواست HTTP، از یک gateway برای دریافت فایل از طریق FTP استفاده کنید. یا می توانید یک پیام رمزگذاری شده از طریق SSL را دریافت کنید و آن را به HTTP (دروازه های شتاب دهنده امنیتی سمت کلاینت) تبدیل کنید یا HTTP را به یک پیام HTTPS ایمن تر (دروازه های امنیتی سمت سرور) تبدیل کنید.
Tunnel ها
تونل ها از متد درخواست CONNECT استفاده می کنند. آنها ارسال داده های غیر HTTP را از طریق HTTP امکان پذیر می کنند. متد CONNECT از tunnel می خواهد تا یک connection به سرور مقصد باز کند و داده ها را بین کلاینت و سرور انتقال دهد.
CONNECT request:
|
1 2 3 |
CONNECT api.github.com:443 HTTP/1.0 User-Agent: Chrome/58.0.3029.110 Accept: text/html,application/xhtml+xml,application/xml |
CONNECT response:
|
1 2 |
HTTP/1.0 200 Connection Established Proxy-agent: Netscape-Proxy/1.1 |
CONNECT response برخلاف HTTP response معمولی، نیازی به تعیین Content-Type ندارد.
هنگامی که connection برقرار شد، می توانیم داده ها را مستقیماً بین کلاینت و سرور ارسال کنیم.
Relay ها
Relay ها، قانون شکنان دنیای HTTP هستند و نیازی به رعایت قوانین HTTP ندارند. آنها نسخههای پیش پا افتاده ای از پراکسیها هستند که هر اطلاعاتی را که دریافت میکنند را تا زمانی که بتوانند با استفاده از حداقل اطلاعات پیامهای درخواستی ارتباط برقرار کنند، انتقال میدهند.
Web Crawler ها

همچنین به عنکبوت ها نیز معروف هستند، ربات هایی هستند که در شبکه جهانی وب می خزند و محتوای آن را ایندکس می کنند. بنابراین، خزنده وب یک ابزار ضروری برای موتورهای جستجو و بسیاری از وب سایت های دیگر است.
خزنده وب یک نرم افزار کاملاً خودکار است و برای کار کردن نیازی به تعامل انسانی ندارد. پیچیدگی خزنده های وب می تواند بسیار متفاوت باشد و برخی از خزنده های وب، نرم افزارهای بسیار پیچیده ای هستند (مانند مواردی که موتورهای جستجو استفاده می کنند).
خزنده های وب، منابع وب سایتی را که بازدید می کنند را استفاده می کنند. به همین دلیل، وبسایتهای عمومی مکانیزمی دارند که به خزندهها میگویند کدام قسمتهای وبسایت را بخزند، یا به آنها میگویند که اصلاً چیزی را مورد خزیدن قرار ندهند. می توانید این کار را با استفاده از robots.txt (استاندارد حذف ربات ها) انجام دهید.
البته، از آنجایی که robots.txt فقط یک استاندارد است، نمیتواند از خزندههای وب ناخوانده برای خزیدن وبسایت جلوگیری کند. برخی از رباتهای مخرب شامل دروکننده های ایمیل، هرزنامهها و بدافزارها هستند.
در اینجا چند نمونه از فایل های robots.txt آورده شده است:
|
1 2 |
User-agent: * Disallow: / |
این یکی به همه خزنده ها می گوید که بیرون بمانند.
|
1 2 3 4 |
User-agent: * Disallow: /somefolder/ Disallow: /notinterestingstuff/ Disallow: /directory/file.html |
و این یکی فقط به این دو دایرکتوری خاص و یک فایل واحد اشاره دارد.
|
1 2 |
User-agent: Googlebot Disallow: /private/ |
میتوانید مانند این مورد، خزنده خاصی را از خزیدن غیر مجاز کنید.
اما با توجه به ماهیت گسترده وب جهانی، حتی قدرتمندترین خزنده هایی که تا به حال ساخته شده اند هم نمی توانند کل وب را بخزند و ایندکس کنند. و به همین دلیل است که از خط مشی انتخاب برای خزیدن مرتبط ترین بخش های وب استفاده می کنند. همچنین، WWW به طور مکرر و پویا تغییر می کند، بنابراین خزنده ها باید از خط مشی freshness برای محاسبه اینکه آیا وب سایت ها را دوباره بازدید کنند یا خیر، استفاده کنند. و از آنجایی که خزندهها میتوانند به راحتی با درخواستهای خیلی سریع و زیاد، سرورها را بیش از حد بارگیری کنند، یک خط مشی politeness وجود دارد. بسیاری از خزنده های شناخته شده از فواصل 20 ثانیه تا 3-4 دقیقه برای نظرسنجی از سرورها استفاده می کنند تا از ایجاد بار روی سرور جلوگیری کنند.
ممکن است اخبار اسرارآمیز وب و شیطانی deep web یا dark web را شنیده باشید. اما این چیزی نیست جز بخشی از وب که عمداً توسط موتورهای جستجو ایندکس نمی شود تا اطلاعات را پنهان کند.
نتیجه گیری
این مقاله، بحث را برای سری آموزش پیرامون HTTP تکمیلتر می کند. اکنون باید تصویر بهتری از نحوه عملکرد HTTP و اینکه چیزهایی بیش از درخواست ها، response ها و status code ها در HTTP وجود دارد داشته باشید. زیرساخت کاملی از قطعات سخت افزاری و نرم افزاری مختلف وجود دارد که HTTP از آنها برای دستیابی به پتانسیل خود به عنوان یک پروتکل application استفاده می کند.
هر مفهومی که در این مقاله درباره آن صحبت کردم به اندازه کافی بزرگ است که یک مقاله کلی یا حتی یک کتاب را پوشش دهد. هدف ما این بود که به طور تقریبی مفاهیم مختلف را به شما ارائه دهیم تا بدانید که چگونه همه اینها با هم هماهنگ می شوند و در صورت نیاز به دنبال چه چیزی باشید.
اگر برخی از توضیحات را کمی کوتاه و نامشخص یافتید و مقالات قبلی من را مشاهده نکرده اید، حتما از قسمت 1 مجموعه و مرجع HTTP که در آن در مورد مفاهیم اولیه HTTP صحبت کرده ام بازدید کنید.
با تشکر از شما که این مقاله را مطالعه کردید و منتظر قسمت 3 این مجموعه از آموزش HTTP باشید که در آن راه های مختلفی را توضیح می دهم که سرورها می توانند برای شناسایی client ها استفاده کنند.